One checkpoint per page
Last lesson you stood up the boundary: clicking Export fires a real validated run that lands on the per-org queue, dedups on the daily key, and completes. But the body still does nothing — it sets pagesDone to 0 and returns. Now you turn that placeholder into a real paginated export where every page is its own durable child run.
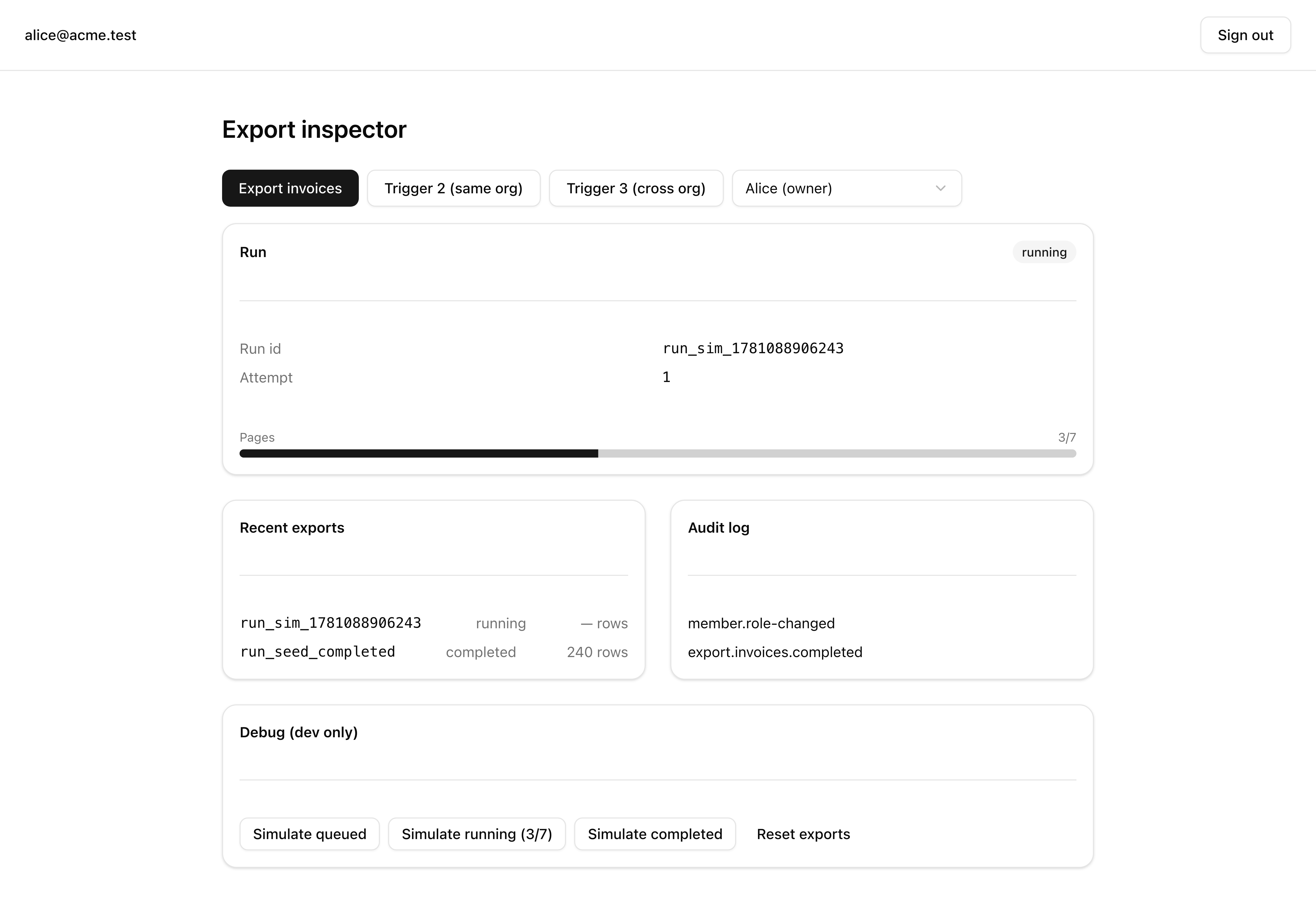
Here is what that buys you on screen. Against a seeded org, clicking Export drives the progress bar to full while the Trigger.dev dashboard grows a paginate-page child run under the export — one child per page, each carrying its own payload and output. The seed gives each invoicing org 200–240 rows and a page holds 500, so a real export is a single page; the count, the loop, and the metadata writes all run end to end regardless. The empty org aborts on the spot with no children at all. And on a parent retry, every completed page comes back from cache on its run-scoped key instead of re-running.
Your mission
Section titled “Your mission”This is where durability stops being a slogan and becomes a shape you can point at. Instead of one long body that walks every row, each page of invoices is spawned as its own paginatePage child run through triggerAndWait, and the parent loops the pages, accumulates the CSV, and streams progress to the watching inspector. The reason to break the work apart this way is the single idea this lesson exists to install: every triggerAndWait is a checkpoint. A multi-page export has one checkpoint per page, so if the worker is killed between pages three and four, the retried parent resumes at page four — it re-issues the same idempotency keys, and the runtime hands back the prior results for the pages that already finished rather than re-running them. The shipped seed gives each org a single page, so that multi-page resume is the reasoned story; the reproducible proof you can run today is cached-on-retry of the one page’s key.
The key that makes resume work is idempotencyKeys.create([organizationId, 'page', String(page)]), and its default scope: 'run' is doing the load-bearing work. Run scope namespaces the key to the parent run id, so the cache is per-run and the v4 SDK hashes the parts together for you instead of you hand-splicing ${ctx.run.id}:page:${page}. The parts array is string[], which is why the numeric page is wrapped in String(page) — a raw number is rejected. Two tempting mistakes break this. Reaching for scope: 'global' collides across runs and hands every export the first one’s page result. Folding Date.now() into the key makes it change on every attempt, so a retry re-runs everything the cache was supposed to skip. The right key is boring on purpose: the same inputs always produce the same string.
The page read goes through listInvoices({ orgId, view: 'active', cursor, pageSize: 500 }) — the cursor pagination you built earlier in the course. The cursor is the natural restart point and stays stable across writes, so a row inserted between two pages is still covered correctly rather than shifting the window under you. Progress flows through run.metadata: the parent writes pagesTotal once after counting, and pagesDone after each page. It writes both from the parent, not the child, because the parent’s view is the one the user sees — forgetting the pagesDone write is the classic bug where the export completes but the bar never moves off zero. And metadata is the module-level @trigger.dev/sdk import, not a field you destructure off the run’s second argument, which only exposes ctx, init, and signal.
An empty resultset is a permanent failure: the same inputs will never produce rows, so retrying is pure waste. On total === 0 the body throws AbortTaskRunError rather than a plain Error — a plain throw would burn all three configured retries before failing, while the abort stops on the first attempt. The rule worth memorizing: permanents abort, transients throw. The loop itself is sequential, a for with an await inside, because parallelizing the pages with Promise.all would race the queue’s concurrency limit and reorder the rows — sequential is the safe default unless the rows carry no order requirement.
Two things stay out of scope here. The CSV is accumulated in memory across pages, which is fine because the per-org row cap bounds it to a few megabytes for the seed; a production org with 100k+ invoices would need each child to stream straight to object storage instead, which lands in the next chapter. And the email step stays empty — the body ends by logging the CSV size and storing a placeholder downloadUrl on metadata, both of which the next lesson picks up.
paginate-page child run per page (one for the single-page seed orgs), each parented under the export run with its own payload and output.pagesTotal is set once from the count and pagesDone is incremented per page, so the bar reflects real per-page advancement rather than a fixed or fabricated value.[organizationId, 'page', String(page)], so a parent retry re-issues the same key and the runtime returns the completed page’s cached result instead of re-executing it; the run reaches completed with the same runId.org_empty fails on the first attempt with no retries, via AbortTaskRunError, and spawns no paginate-page children.Coding time
Section titled “Coding time”Implement trigger/paginate-page.ts and grow the exportInvoices body against the brief, the reference signatures from the project overview, and the tests. Try it before opening the solution below.
Reference solution and walkthrough
Start with the child, because the parent calls it. paginatePage is a schemaTask that reads exactly one page and returns the CSV fragment for that page along with the cursor for the next one.
import { schemaTask } from '@trigger.dev/sdk/v3';import { z } from 'zod';
import { listInvoices } from '@/db/queries/invoices';import { rowsToCsv } from '@/lib/exports/to-csv';
export const paginatePage = schemaTask({ id: 'paginate-page', schema: z.strictObject({ organizationId: z.string().min(1), page: z.int().nonnegative(), cursor: z.string().nullable(), }), run: async ({ organizationId, cursor }) => { const { rows, nextCursor } = await listInvoices({ orgId: organizationId, view: 'active', cursor, pageSize: 500, }); return { csv: rowsToCsv(rows), nextCursor, rowCount: rows.length }; },});The payload is a strict object: organizationId is z.string().min(1) for the same base62-id reason as the parent, page is a non-negative int, and cursor is z.string().nullable() — null for page zero, the previous page’s cursor after that. The body destructures only what it reads (organizationId and cursor; page rides along for the parent’s key construction and the payload record on the dashboard). listInvoices re-derives tenancy through tenantDb internally, so the child never needs request context. rowsToCsv is the pure projection that turns the rows into an RFC-4180 fragment. The child returns nextCursor so the parent can advance to the next page, and rowCount so the parent can see how much each page produced.
Now grow the parent body. This block has several moving parts that are easy to get subtly wrong — the abort guard, the key construction, the two metadata writes, the cursor advance — so step through it part by part.
const PAGE_SIZE = 500;
// ...inside run: async ({ organizationId, requestedBy }, { ctx }) => { const total = await countInvoices({ orgId: organizationId }); if (total === 0) { throw new AbortTaskRunError( new ExportError('EMPTY_RESULTSET', 'no invoices to export').message, ); }
const pagesTotal = Math.ceil(total / PAGE_SIZE); metadata.set('pagesTotal', pagesTotal);
let csv = ''; let cursor: string | null = null; for (let page = 0; page < pagesTotal; page++) { const result = await paginatePage .triggerAndWait( { organizationId, page, cursor }, { idempotencyKey: await idempotencyKeys.create([ organizationId, 'page', String(page), ]), }, ) .unwrap();
csv += result.csv; cursor = result.nextCursor;
metadata.set('pagesDone', page + 1); }
console.log('export-invoices csv built', { bytes: csv.length });
// The placeholder download URL — the next chapter wires the real R2 link. const downloadUrl = `https://example.com/exports/${ctx.run.id}.csv`; metadata.set('downloadUrl', downloadUrl);PAGE_SIZE is a module-level constant, and countInvoices runs first. You count before any child fires so pagesTotal is known up front — the progress bar needs a denominator, and the count is also where you catch the empty case before spending any work.
const PAGE_SIZE = 500;
// ...inside run: async ({ organizationId, requestedBy }, { ctx }) => { const total = await countInvoices({ orgId: organizationId }); if (total === 0) { throw new AbortTaskRunError( new ExportError('EMPTY_RESULTSET', 'no invoices to export').message, ); }
const pagesTotal = Math.ceil(total / PAGE_SIZE); metadata.set('pagesTotal', pagesTotal);
let csv = ''; let cursor: string | null = null; for (let page = 0; page < pagesTotal; page++) { const result = await paginatePage .triggerAndWait( { organizationId, page, cursor }, { idempotencyKey: await idempotencyKeys.create([ organizationId, 'page', String(page), ]), }, ) .unwrap();
csv += result.csv; cursor = result.nextCursor;
metadata.set('pagesDone', page + 1); }
console.log('export-invoices csv built', { bytes: csv.length });
// The placeholder download URL — the next chapter wires the real R2 link. const downloadUrl = `https://example.com/exports/${ctx.run.id}.csv`; metadata.set('downloadUrl', downloadUrl);The empty-resultset guard. total === 0 is a permanent failure — the same inputs will never produce rows — so it throws AbortTaskRunError, which stops on the first attempt. A plain throw would be treated as transient and burn all three configured retries before giving up. Permanents abort, transients throw.
const PAGE_SIZE = 500;
// ...inside run: async ({ organizationId, requestedBy }, { ctx }) => { const total = await countInvoices({ orgId: organizationId }); if (total === 0) { throw new AbortTaskRunError( new ExportError('EMPTY_RESULTSET', 'no invoices to export').message, ); }
const pagesTotal = Math.ceil(total / PAGE_SIZE); metadata.set('pagesTotal', pagesTotal);
let csv = ''; let cursor: string | null = null; for (let page = 0; page < pagesTotal; page++) { const result = await paginatePage .triggerAndWait( { organizationId, page, cursor }, { idempotencyKey: await idempotencyKeys.create([ organizationId, 'page', String(page), ]), }, ) .unwrap();
csv += result.csv; cursor = result.nextCursor;
metadata.set('pagesDone', page + 1); }
console.log('export-invoices csv built', { bytes: csv.length });
// The placeholder download URL — the next chapter wires the real R2 link. const downloadUrl = `https://example.com/exports/${ctx.run.id}.csv`; metadata.set('downloadUrl', downloadUrl);Math.ceil(total / PAGE_SIZE) rounds up so a partial last page still gets its own iteration. metadata.set('pagesTotal', ...) writes the total once, before the loop — metadata is the module-level @trigger.dev/sdk import, not a field on the run’s second argument.
const PAGE_SIZE = 500;
// ...inside run: async ({ organizationId, requestedBy }, { ctx }) => { const total = await countInvoices({ orgId: organizationId }); if (total === 0) { throw new AbortTaskRunError( new ExportError('EMPTY_RESULTSET', 'no invoices to export').message, ); }
const pagesTotal = Math.ceil(total / PAGE_SIZE); metadata.set('pagesTotal', pagesTotal);
let csv = ''; let cursor: string | null = null; for (let page = 0; page < pagesTotal; page++) { const result = await paginatePage .triggerAndWait( { organizationId, page, cursor }, { idempotencyKey: await idempotencyKeys.create([ organizationId, 'page', String(page), ]), }, ) .unwrap();
csv += result.csv; cursor = result.nextCursor;
metadata.set('pagesDone', page + 1); }
console.log('export-invoices csv built', { bytes: csv.length });
// The placeholder download URL — the next chapter wires the real R2 link. const downloadUrl = `https://example.com/exports/${ctx.run.id}.csv`; metadata.set('downloadUrl', downloadUrl);The sequential for loop. Each page is its own paginatePage.triggerAndWait(...).unwrap() child run — and every triggerAndWait is a checkpoint. The idempotencyKeys.create([organizationId, 'page', String(page)]) key defaults to scope: 'run', so on a parent retry the same key returns the completed page’s cached result instead of re-running it.
const PAGE_SIZE = 500;
// ...inside run: async ({ organizationId, requestedBy }, { ctx }) => { const total = await countInvoices({ orgId: organizationId }); if (total === 0) { throw new AbortTaskRunError( new ExportError('EMPTY_RESULTSET', 'no invoices to export').message, ); }
const pagesTotal = Math.ceil(total / PAGE_SIZE); metadata.set('pagesTotal', pagesTotal);
let csv = ''; let cursor: string | null = null; for (let page = 0; page < pagesTotal; page++) { const result = await paginatePage .triggerAndWait( { organizationId, page, cursor }, { idempotencyKey: await idempotencyKeys.create([ organizationId, 'page', String(page), ]), }, ) .unwrap();
csv += result.csv; cursor = result.nextCursor;
metadata.set('pagesDone', page + 1); }
console.log('export-invoices csv built', { bytes: csv.length });
// The placeholder download URL — the next chapter wires the real R2 link. const downloadUrl = `https://example.com/exports/${ctx.run.id}.csv`; metadata.set('downloadUrl', downloadUrl);Accumulate this page’s CSV fragment into csv, then advance cursor to the child’s nextCursor. The cursor is the natural restart point and stays stable across writes, so a row inserted mid-export is still covered rather than shifting the window.
const PAGE_SIZE = 500;
// ...inside run: async ({ organizationId, requestedBy }, { ctx }) => { const total = await countInvoices({ orgId: organizationId }); if (total === 0) { throw new AbortTaskRunError( new ExportError('EMPTY_RESULTSET', 'no invoices to export').message, ); }
const pagesTotal = Math.ceil(total / PAGE_SIZE); metadata.set('pagesTotal', pagesTotal);
let csv = ''; let cursor: string | null = null; for (let page = 0; page < pagesTotal; page++) { const result = await paginatePage .triggerAndWait( { organizationId, page, cursor }, { idempotencyKey: await idempotencyKeys.create([ organizationId, 'page', String(page), ]), }, ) .unwrap();
csv += result.csv; cursor = result.nextCursor;
metadata.set('pagesDone', page + 1); }
console.log('export-invoices csv built', { bytes: csv.length });
// The placeholder download URL — the next chapter wires the real R2 link. const downloadUrl = `https://example.com/exports/${ctx.run.id}.csv`; metadata.set('downloadUrl', downloadUrl);pagesDone is written from the parent, once per page, because the parent’s run is the one the inspector polls. Omit this single line and you get the classic bug: the export completes, every page succeeds, and the bar sits frozen at zero.
const PAGE_SIZE = 500;
// ...inside run: async ({ organizationId, requestedBy }, { ctx }) => { const total = await countInvoices({ orgId: organizationId }); if (total === 0) { throw new AbortTaskRunError( new ExportError('EMPTY_RESULTSET', 'no invoices to export').message, ); }
const pagesTotal = Math.ceil(total / PAGE_SIZE); metadata.set('pagesTotal', pagesTotal);
let csv = ''; let cursor: string | null = null; for (let page = 0; page < pagesTotal; page++) { const result = await paginatePage .triggerAndWait( { organizationId, page, cursor }, { idempotencyKey: await idempotencyKeys.create([ organizationId, 'page', String(page), ]), }, ) .unwrap();
csv += result.csv; cursor = result.nextCursor;
metadata.set('pagesDone', page + 1); }
console.log('export-invoices csv built', { bytes: csv.length });
// The placeholder download URL — the next chapter wires the real R2 link. const downloadUrl = `https://example.com/exports/${ctx.run.id}.csv`; metadata.set('downloadUrl', downloadUrl);The lesson’s hand-off point. The body logs the CSV size and stores a placeholder downloadUrl on metadata — the next lesson wires the email step and the real download link in its place.
A few decisions are worth pausing on.
Why the count comes first. You need pagesTotal before the first child fires so the progress bar has a denominator, and the count read is also where you catch the empty case before spending any work. pagesTotal = Math.ceil(total / PAGE_SIZE) rounds up so a partial last page still gets its own iteration.
The idempotency key is the whole point. Walk the resume story concretely: a four-page export crashes after page three commits. The parent retries with the same ctx.run.id, so on page zero through two idempotencyKeys.create([organizationId, 'page', String(page)]) produces the exact same keys it produced the first time, and triggerAndWait returns those children’s cached results without re-running them; page three is the first uncompleted page and actually executes. That only holds because the key is deterministic and run-scoped. The two broken shapes are worth seeing side by side with the correct one — the difference is one option, and it silently destroys the cache.
// scope: 'global' collides across runs — every export reuses the first run's page result.idempotencyKey: await idempotencyKeys.create( [organizationId, 'page', String(page)], { scope: 'global' },)
// ...or folding Date.now() in changes the key every attempt, so a retry re-runs everything.idempotencyKey: await idempotencyKeys.create([ organizationId, 'page', String(page), String(Date.now()),])Both defeat the cache. scope: 'global' namespaces the key app-wide instead of per-run, so every export’s page zero collides on one key and hands back the first run’s result. Folding Date.now() in makes the key change on every attempt, so a retry finds nothing cached and re-runs every page.
idempotencyKey: await idempotencyKeys.create([ organizationId, 'page', String(page),])Boring on purpose. scope defaults to 'run', so the key is namespaced to ctx.run.id and the v4 SDK hashes the parts together for you. The same parts always produce the same string, so a parent retry re-issues the identical key and gets a cache hit. page is wrapped in String(page) because the parts array is string[] — a raw number is rejected.
The idempotencyKeys.create mechanics — the scope semantics and why run scope replaces the manual run-id prefix — were covered in the durable-execution lesson on idempotency keys in the previous chapter; reach back there if the scope distinction feels thin.
.unwrap() on the result. triggerAndWait returns a result wrapper that distinguishes a completed child from a failed one; .unwrap() gives you the child’s return value directly and rethrows if the child failed, which is what you want here — a failed page should propagate and let the parent’s retry policy handle it.
Abort versus throw. AbortTaskRunError wraps a string message, so the body passes new ExportError('EMPTY_RESULTSET', ...).message — the message off a fresh ExportError instance, not the instance itself. The ExportError class exists to keep the export error codes in one open union; here it is only the source of a consistent message. The reason to abort rather than throw is cost: a plain throw is treated as a transient failure and retried up to maxAttempts, so an org that legitimately has zero invoices would fail three times before giving up. The same abort-versus-throw distinction is in the durable-execution lesson in the previous chapter.
Cursor stability. listInvoices paginates on a createdAt-descending cursor, so each page reads from the last page’s cursor rather than by offset. That is what keeps the read stable when rows are written mid-export — an offset would shift every page when a row is inserted, duplicating or skipping rows. The cursor primitive and its stability guarantees were covered with the list queries earlier in the course; this just reuses them.
Why pagesDone is set from the parent. The child knows it finished its page, but the parent owns the user-facing progress — it is the run the inspector polls. So the parent increments pagesDone after each successful page. Omit that one line and you get the most common version of this bug: the export runs to completion, every page succeeds, and the bar sits frozen at zero because nothing ever told the user-facing run how far it got.
metadata is the import, not a run-param field. It comes from the module-level @trigger.dev/sdk import at the top of the file. The metadata channel and how an inspecting client reads it were covered in the metadata lesson in the previous chapter.
The loop is sequential on purpose. Each iteration awaits its page before the next begins, which keeps the rows in order as they accumulate into csv. Promise.all-ing the pages would fire them concurrently, and with the queue at concurrencyLimit: 1 they would serialize anyway and their completion order would no longer match page order, scrambling the CSV. Sequential is both correct and, here, not even slower.
In-memory accumulation is a deliberate ceiling. Concatenating every page into one csv string is fine for the seed because the per-org row cap keeps it small. For a six-figure-row org you would instead stream each page straight into an object-storage multipart upload from inside the child, never holding the whole file in memory — that is exactly what the next chapter builds.
The body ends, for this lesson, at the placeholder downloadUrl on metadata. The email child and the closing transaction are the next lesson’s work, so for now the body returns the same placeholder-shaped value it returned before:
// The email send and the closing exports-row + audit transaction land next lesson. return { ok: true };The run vs global scope distinction and idempotencyKeys.create — exactly the per-page key this lesson hinges on.
How triggerAndWait checkpoints the parent and how .unwrap() returns the child's result or rethrows on failure.
Why AbortTaskRunError stops on the first attempt while a plain throw burns every retry — permanents abort, transients throw.
Moment of truth
Section titled “Moment of truth”Run the lesson’s test suite:
pnpm test:lesson 3The gates run your task bodies in process — they intercept schemaTask to capture each run config, then call it directly with a recording metadata store and a fake paginatePage.triggerAndWait that emulates the platform’s idempotency dedup. Expect every test green:
✓ Requirement 2 — metadata drives real per-page progress (2) ✓ Requirement 3 — run-scoped per-page key returns cached on retry (3) ✓ Requirement 5 — empty org aborts without retries and spawns no children (2) ✓ Requirement 4 — the page child emits a single-page CSV fragment (2)
Test Files 1 passed (1) Tests 9 passed (9)Green means pagesTotal is set once from the count and pagesDone advances per page, the run-scoped key returns the completed page from cache on a parent retry without re-executing it, the child emits the correct single-page CSV fragment and advances the cursor, and the empty org aborts with no children. The rest needs a live worker and the dashboard — confirm these by hand:
paginate-page child with its payload and output, parented under the export run.completed with the same runId. (The kill-the-worker-mid-page variant needs a multi-page org the seed does not ship — reason it through against the single page.)org_empty. The body throws AbortTaskRunError; the dashboard shows one attempt, no retries, and no paginate-page children.idempotencyKey comes from idempotencyKeys.create([organizationId, 'page', 0]) (run-scoped to the parent), force a parent retry, and confirm the same key returns the cached output instead of re-executing.