Cache the reads
Instrument the three reads the invoices surface depends on — the paginated list, the per-org totals summary, and the single-invoice detail — so each serves from cache instead of recomputing on every request.
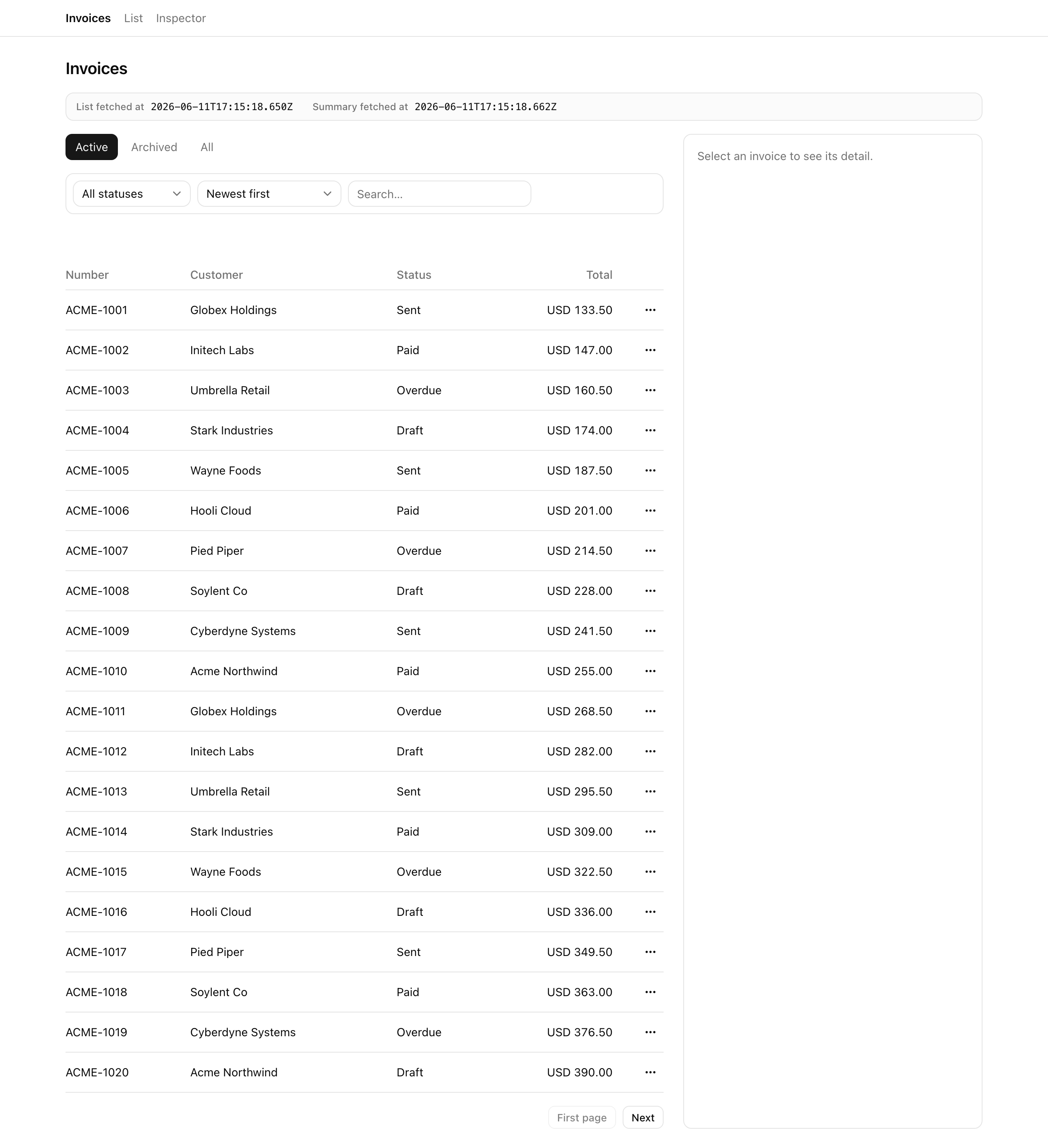
When you finish, opening /invoices shows a listFetchedAt and a summaryFetchedAt that hold steady when you reload the page, and an invoice detail page shows a fetchedAt that holds steady too. Those timestamps holding still is the whole point: the framework is serving you a cached value rather than running the query again. The starter renders the same strip today, but every refresh stamps a new time, because nothing is cached yet.
Your mission
Section titled “Your mission”Take those three reads and turn them into cached functions without touching the query logic underneath, the same logic you wrote in The production list view. A cached read opens its body with 'use cache', picks a cacheLife profile that sets how stale the result may get, and emits its invalidation tags through the shared tags.ts helpers — the directives wrap the existing scoped query, they do not replace it. The mechanics of use cache and cacheLife were taught in The Cache Components rendering model; the tag scheme and the fetchedAt discipline in Cache decisions as architecture. This lesson applies them, it does not re-derive them.
The decision you are actually installing here is which reads earn the directive at all. The list, the summary, and the detail are read often and tolerate a few minutes of staleness, so they take use cache. The toolbar and every Client Component stay dynamic, because they read request-scoped URL state — adding use cache to one of those is the trap, and the reason caching is opt-in and dynamic is the right default for an authenticated surface.
The cache backend does not expose hit or miss to your code. Your only window into cache state is a fetchedAt timestamp that each cached function computes once when it runs and freezes into the entry — stable across requests means a hit, advancing means a miss. The starter already builds the <FetchedAtStrip /> and already returns a fetchedAt line from each read; your job is to wrap that return in 'use cache' so the timestamp is computed per entry rather than per request. The rest of the project reads cache state off this proxy.
Constraints. Two rules shape the tags. Every tag string lives only in tags.ts — lowercase, colon-delimited, scope first — so read sites and write sites import the same function and a grep for a raw org: literal anywhere else is a regression. And a cached function’s tags depend only on its arguments: orgId is passed in by the page, never read from the session inside the cached body. Reach for getSession() or cookies() inside a cached read and the cache key silently leaks request state, which is how one tenant ends up reading another’s data. The detail read is the one place a read carries two tags — the record tag and the org tag — so that either a single-invoice write or an org-wide change invalidates it.
Out of scope. Any updateTag or revalidateTag wiring — that is the next two lessons. Per-user 'use cache: private' caches, a call deferred until a workload justifies it. And edge or CDN tuning.
tags.ts each return their scoped string, vary by orgId, and are the only place a raw org:/invoice: literal exists.minutes profile, carries the org list tag, returns a fetchedAt, and still serves the seeded active rows.hours profile, carries the org summary tag, returns a fetchedAt, and reads correctly against the empty seed via the live-aggregate fallback.?status=paid) returns a different result set, and a fixed argument set returns the same rows every time — each distinct argument set is its own cache key.minutes profile, carries both the record tag and the org list tag, and returns a fetchedAt.getSession(), cookies(), or headers() — every emitted tag is derived from the orgId argument the page passes in.cacheLife readout shows listInvoices: 'minutes', getInvoiceDetail: 'minutes', and getOrgInvoiceSummary: 'hours'.Coding time
Section titled “Coding time”Implement tags.ts, profiles.ts, and the three cached reads against the brief and the test suite first. Then open the reference walkthrough below and read how each decision was made.
Reference solution and walkthrough
tags.ts — one home for every tag string
Section titled “tags.ts — one home for every tag string”The starter ships invoiceTags as three stubs returning ''. Fill each one with the template that is the tag scheme: scope first, lowercase, colon-delimited.
// The single source of truth for tag strings. Read sites (cached reads) and write// sites (actions, the recompute job) import these helpers — a raw `org:`/`invoice:`// literal anywhere else is a regression. Each is a pure function of its arguments.// Tag strings are lowercase, colon-delimited, scope first.export const invoiceTags = { list: (orgId: string): string => `org:${orgId}:invoices`, record: (orgId: string, id: string): string => `org:${orgId}:invoice:${id}`, summary: (orgId: string): string => `org:${orgId}:summary`,};Each helper is a pure function of its arguments — the same inputs always produce the same string, with no Date.now(), no random suffix, nothing ambient. That purity is not decoration: a read tags itself with invoiceTags.list(orgId) and a write later invalidates with the very same call, so the two strings must match character-for-character. Centralizing them in one module is what guarantees they do. This is the tags.ts convention from Cache decisions as architecture; here you are building the file the whole project imports.
profiles.ts — the readout’s source of truth
Section titled “profiles.ts — the readout’s source of truth”The inspector’s cacheLife readout needs to display one profile per cached function, and it does not parse the query bodies to find them — it reads this map. Populate it to mirror the profiles you set in queries.ts.
// Mirrors the `cacheLife` profile chosen for each cached read, so the inspector's// readout can show it without parsing the query bodies. Keyed by cached-function// name to match the directive trio in queries.ts.export const cacheProfiles: Record<string, { profile: string }> = { listInvoices: { profile: 'minutes' }, getInvoiceDetail: { profile: 'minutes' }, getOrgInvoiceSummary: { profile: 'hours' },};This map is the entire reason requirement 7 is satisfiable. Until you fill it the readout shows dash placeholders; once it matches the directives, the panel reads listInvoices: 'minutes', getInvoiceDetail: 'minutes', getOrgInvoiceSummary: 'hours'. It is a deliberately dumb mirror, not a parser — you keep it in step with queries.ts by hand.
queries.ts — the directive stack
Section titled “queries.ts — the directive stack”Each read gets the same three-line opener and nothing else changes below it. The list read is the template for the pattern; step through it.
export const listInvoices = async ({ orgId, view, status, sort, q, cursor, role, pageSize = 20,}: ListInvoicesArgs): Promise<ListInvoicesResult & { fetchedAt: string }> => { 'use cache'; cacheLife('minutes'); cacheTag(invoiceTags.list(orgId)); const scoped = scopedInvoices(orgId); const resolved = resolveView(view, role); const base = resolved === 'archived' ? scoped.archived() : resolved === 'all' ? scoped.includingDeleted() : scoped.active();
const needle = q.trim().toLowerCase();
// Compose status/search/sort/cursor onto the chosen view, then page it. const paged = base .filter((inv) => (status ? inv.status === status : true)) .filter((inv) => needle ? inv.customerName.toLowerCase().includes(needle) || inv.number.toLowerCase().includes(needle) : true, ) .sort((a, b) => compareBySort(a, b, sort)) .cursorAfter(cursor);
const page = paged.take(pageSize); const nextCursor = paged.hasMoreThan(pageSize) ? (page[page.length - 1]?.id ?? null) : null;
return { rows: page, nextCursor, hasPrev: paged.hasPrev(), fetchedAt: new Date().toISOString(), };};The destructured signature — orgId, view, status, sort, q, cursor, role, pageSize all arrive as serializable arguments, which is what lets them participate in the cache key.
export const listInvoices = async ({ orgId, view, status, sort, q, cursor, role, pageSize = 20,}: ListInvoicesArgs): Promise<ListInvoicesResult & { fetchedAt: string }> => { 'use cache'; cacheLife('minutes'); cacheTag(invoiceTags.list(orgId)); const scoped = scopedInvoices(orgId); const resolved = resolveView(view, role); const base = resolved === 'archived' ? scoped.archived() : resolved === 'all' ? scoped.includingDeleted() : scoped.active();
const needle = q.trim().toLowerCase();
// Compose status/search/sort/cursor onto the chosen view, then page it. const paged = base .filter((inv) => (status ? inv.status === status : true)) .filter((inv) => needle ? inv.customerName.toLowerCase().includes(needle) || inv.number.toLowerCase().includes(needle) : true, ) .sort((a, b) => compareBySort(a, b, sort)) .cursorAfter(cursor);
const page = paged.take(pageSize); const nextCursor = paged.hasMoreThan(pageSize) ? (page[page.length - 1]?.id ?? null) : null;
return { rows: page, nextCursor, hasPrev: paged.hasPrev(), fetchedAt: new Date().toISOString(), };};'use cache' is the very first statement in the body, before any other line runs. It marks everything below as a cached Server Function; the Next compiler strips it at build and wires a real cache scope.
export const listInvoices = async ({ orgId, view, status, sort, q, cursor, role, pageSize = 20,}: ListInvoicesArgs): Promise<ListInvoicesResult & { fetchedAt: string }> => { 'use cache'; cacheLife('minutes'); cacheTag(invoiceTags.list(orgId)); const scoped = scopedInvoices(orgId); const resolved = resolveView(view, role); const base = resolved === 'archived' ? scoped.archived() : resolved === 'all' ? scoped.includingDeleted() : scoped.active();
const needle = q.trim().toLowerCase();
// Compose status/search/sort/cursor onto the chosen view, then page it. const paged = base .filter((inv) => (status ? inv.status === status : true)) .filter((inv) => needle ? inv.customerName.toLowerCase().includes(needle) || inv.number.toLowerCase().includes(needle) : true, ) .sort((a, b) => compareBySort(a, b, sort)) .cursorAfter(cursor);
const page = paged.take(pageSize); const nextCursor = paged.hasMoreThan(pageSize) ? (page[page.length - 1]?.id ?? null) : null;
return { rows: page, nextCursor, hasPrev: paged.hasPrev(), fetchedAt: new Date().toISOString(), };};cacheLife sets the staleness ceiling. minutes is right for a read this often edited — if an invalidation ever fails to fire, a stale list self-heals within a few minutes rather than lingering.
export const listInvoices = async ({ orgId, view, status, sort, q, cursor, role, pageSize = 20,}: ListInvoicesArgs): Promise<ListInvoicesResult & { fetchedAt: string }> => { 'use cache'; cacheLife('minutes'); cacheTag(invoiceTags.list(orgId)); const scoped = scopedInvoices(orgId); const resolved = resolveView(view, role); const base = resolved === 'archived' ? scoped.archived() : resolved === 'all' ? scoped.includingDeleted() : scoped.active();
const needle = q.trim().toLowerCase();
// Compose status/search/sort/cursor onto the chosen view, then page it. const paged = base .filter((inv) => (status ? inv.status === status : true)) .filter((inv) => needle ? inv.customerName.toLowerCase().includes(needle) || inv.number.toLowerCase().includes(needle) : true, ) .sort((a, b) => compareBySort(a, b, sort)) .cursorAfter(cursor);
const page = paged.take(pageSize); const nextCursor = paged.hasMoreThan(pageSize) ? (page[page.length - 1]?.id ?? null) : null;
return { rows: page, nextCursor, hasPrev: paged.hasPrev(), fetchedAt: new Date().toISOString(), };};cacheTag stamps the entry with the org’s list tag, derived purely from the orgId argument — never from session. A later org-level write invalidates exactly the entries carrying this tag.
export const listInvoices = async ({ orgId, view, status, sort, q, cursor, role, pageSize = 20,}: ListInvoicesArgs): Promise<ListInvoicesResult & { fetchedAt: string }> => { 'use cache'; cacheLife('minutes'); cacheTag(invoiceTags.list(orgId)); const scoped = scopedInvoices(orgId); const resolved = resolveView(view, role); const base = resolved === 'archived' ? scoped.archived() : resolved === 'all' ? scoped.includingDeleted() : scoped.active();
const needle = q.trim().toLowerCase();
// Compose status/search/sort/cursor onto the chosen view, then page it. const paged = base .filter((inv) => (status ? inv.status === status : true)) .filter((inv) => needle ? inv.customerName.toLowerCase().includes(needle) || inv.number.toLowerCase().includes(needle) : true, ) .sort((a, b) => compareBySort(a, b, sort)) .cursorAfter(cursor);
const page = paged.take(pageSize); const nextCursor = paged.hasMoreThan(pageSize) ? (page[page.length - 1]?.id ?? null) : null;
return { rows: page, nextCursor, hasPrev: paged.hasPrev(), fetchedAt: new Date().toISOString(), };};The return is unchanged from the starter except that it now lives inside a cached body, so fetchedAt is computed once per cache entry. A stable timestamp across requests is your hit signal.
The order inside the body is load-bearing: 'use cache' first, then cacheLife, then cacheTag. The directive marks the boundary; the two calls configure that boundary and must run inside it. The query logic below — scopedInvoices, the filter chain, the cursor paging — is exactly the code you already shipped in The production list view. You wrapped it, you did not rewrite it.
The fetchedAt: new Date().toISOString() line was already in the starter’s return. The change that makes it meaningful is the 'use cache' above it. Without the directive that expression runs on every request and the timestamp always advances; with it, the line is part of the cached body, so it runs once when the entry is computed and the same frozen string comes back on every hit. That is precisely why a stable fetchedAt is a trustworthy hit signal and an advancing one is a miss.
Why minutes and not seconds or hours? The list is read constantly and edited often, so you want a low staleness ceiling — if some future invalidation path fails to fire, you’d rather a stale list self-correct within a couple of minutes than serve last hour’s rows. The detail read gets the same minutes for the same reason. The summary is different, and that is the next read.
The summary read takes the same opener with the hours profile, and tags the org summary:
export const getOrgInvoiceSummary = async ( orgId: string,): Promise<{ totalCount: number; totalAmount: number; updatedAt: string; fetchedAt: string;}> => { 'use cache'; cacheLife('hours'); cacheTag(invoiceTags.summary(orgId)); const row = getSummaryRow(orgId); if (row) { return { totalCount: row.totalCount, totalAmount: row.totalAmount, updatedAt: row.updatedAt, fetchedAt: new Date().toISOString(), }; }
// Live fallback: count + sum(total) over the active (non-archived, // non-deleted) rows for this org. const active = scopedInvoices(orgId).active().take(Number.MAX_SAFE_INTEGER); const totalCount = active.length; const totalAmount = active.reduce((sum, inv) => sum + Number(inv.total), 0); return { totalCount, totalAmount, updatedAt: new Date(0).toISOString(), fetchedAt: new Date().toISOString(), };};hours is the right ceiling here because the summary is refreshed explicitly by a background job (lesson 4) and only ever matters on the dashboard, not on the per-row edit path — a longer staleness window means fewer recomputes for a number that moves slowly. Note the fallback already in the body: when no summaries row exists yet, the read computes a live count and sum over the active rows. The store seeds the summaries map empty, so without that branch the very first summary read would return zeros. With it, the cached read works from minute one; once the job lands and writes a summaries row, the read serves that instead. You do not write the fallback — it is provided — but it is why requirement 3 holds against the empty seed.
The detail read is the one that carries two tags. Step through its tag call.
export const getInvoiceDetail = async ({ orgId, id, role,}: GetInvoiceDetailArgs): Promise<(Invoice & { fetchedAt: string }) | null> => { 'use cache'; cacheLife('minutes'); // The tag union: either a record-level write or an org-level (list) write // reaches the detail entry. cacheTag(invoiceTags.record(orgId, id), invoiceTags.list(orgId)); // Active + archived rows load for everyone (archived so the row can be // restored); a soft-deleted row only loads for an admin. const scoped = scopedInvoices(orgId); const live = scoped.archived().find((inv) => inv.id === id); if (live) { return { ...live, fetchedAt: new Date().toISOString() }; } const active = scoped.active().find((inv) => inv.id === id); if (active) { return { ...active, fetchedAt: new Date().toISOString() }; } if (role === 'admin') { const deleted = scoped.includingDeleted().find((inv) => inv.id === id); return deleted ? { ...deleted, fetchedAt: new Date().toISOString() } : null; } return null;};The same opener as the list — 'use cache' then the minutes ceiling, because a single invoice is read and edited just as often as the list.
export const getInvoiceDetail = async ({ orgId, id, role,}: GetInvoiceDetailArgs): Promise<(Invoice & { fetchedAt: string }) | null> => { 'use cache'; cacheLife('minutes'); // The tag union: either a record-level write or an org-level (list) write // reaches the detail entry. cacheTag(invoiceTags.record(orgId, id), invoiceTags.list(orgId)); // Active + archived rows load for everyone (archived so the row can be // restored); a soft-deleted row only loads for an admin. const scoped = scopedInvoices(orgId); const live = scoped.archived().find((inv) => inv.id === id); if (live) { return { ...live, fetchedAt: new Date().toISOString() }; } const active = scoped.active().find((inv) => inv.id === id); if (active) { return { ...active, fetchedAt: new Date().toISOString() }; } if (role === 'admin') { const deleted = scoped.includingDeleted().find((inv) => inv.id === id); return deleted ? { ...deleted, fetchedAt: new Date().toISOString() } : null; } return null;};The tag union. cacheTag takes both invoiceTags.record(orgId, id) and invoiceTags.list(orgId), so this one entry carries two tags.
export const getInvoiceDetail = async ({ orgId, id, role,}: GetInvoiceDetailArgs): Promise<(Invoice & { fetchedAt: string }) | null> => { 'use cache'; cacheLife('minutes'); // The tag union: either a record-level write or an org-level (list) write // reaches the detail entry. cacheTag(invoiceTags.record(orgId, id), invoiceTags.list(orgId)); // Active + archived rows load for everyone (archived so the row can be // restored); a soft-deleted row only loads for an admin. const scoped = scopedInvoices(orgId); const live = scoped.archived().find((inv) => inv.id === id); if (live) { return { ...live, fetchedAt: new Date().toISOString() }; } const active = scoped.active().find((inv) => inv.id === id); if (active) { return { ...active, fetchedAt: new Date().toISOString() }; } if (role === 'admin') { const deleted = scoped.includingDeleted().find((inv) => inv.id === id); return deleted ? { ...deleted, fetchedAt: new Date().toISOString() } : null; } return null;};The record tag scopes to this exact invoice. A write to invoice A invalidates A’s detail and leaves B’s untouched, because record(orgId, A) is a distinct string from record(orgId, B).
export const getInvoiceDetail = async ({ orgId, id, role,}: GetInvoiceDetailArgs): Promise<(Invoice & { fetchedAt: string }) | null> => { 'use cache'; cacheLife('minutes'); // The tag union: either a record-level write or an org-level (list) write // reaches the detail entry. cacheTag(invoiceTags.record(orgId, id), invoiceTags.list(orgId)); // Active + archived rows load for everyone (archived so the row can be // restored); a soft-deleted row only loads for an admin. const scoped = scopedInvoices(orgId); const live = scoped.archived().find((inv) => inv.id === id); if (live) { return { ...live, fetchedAt: new Date().toISOString() }; } const active = scoped.active().find((inv) => inv.id === id); if (active) { return { ...active, fetchedAt: new Date().toISOString() }; } if (role === 'admin') { const deleted = scoped.includingDeleted().find((inv) => inv.id === id); return deleted ? { ...deleted, fetchedAt: new Date().toISOString() } : null; } return null;};The list tag is here too, so a future org-wide change that invalidates the whole list also reaches this detail entry. You tag at the granularity of the writes that should reach the read, not just the read’s own identity.
The two-tag call is the tag-union rule from Cache decisions as architecture applied: a cached read should carry every tag that names a write which ought to refresh it. This detail entry must die when this invoice is edited (the record tag) and also when something invalidates the whole org list (the list tag). Tagging only by the read’s own identity — just the record tag — would leave it stale after an org-wide change. You tag for the writes, not for the read.
The page wiring is already done
Section titled “The page wiring is already done”You may notice the brief never asks you to touch page.tsx. That is on purpose. The list page already destructures fetchedAt off listInvoices and the summary’s fetchedAt, and already feeds both into the strip:
// The page resolves the session and passes `orgId` in — no session/cookies call // ever moves inside a cached read body (the cache key stays a pure function of // its arguments). const { rows, nextCursor, hasPrev, fetchedAt } = await listInvoices({ orgId: session.orgId, role: session.role, ...parsed, }); const summary = await getOrgInvoiceSummary(session.orgId);
return ( <div data-testid="invoices-page" className="space-y-4"> <h1 className="text-xl font-semibold">Invoices</h1>
{/* The cache-state strip renders ABOVE the two-region grid — never a third grid child. */} <FetchedAtStrip listFetchedAt={fetchedAt} summaryFetchedAt={summary.fetchedAt} />This is the half of the tags-are-arguments rule that lives outside the cached body: the page resolves the session here, in the dynamic layer, and passes session.orgId into the read as a plain argument. The cached function never sees the session at all. The edit page does the same with getInvoiceDetail and threads its fetchedAt into the strip as detailFetchedAt. Once your three reads return a frozen fetchedAt, the strip has stable values to show — no component to author.
The minutes / hours profiles you set here, with their exact stale / revalidate / expire timings.
Tagging a cached entry, including the multi-tag call the detail read uses.
Moment of truth
Section titled “Moment of truth”Run the lesson’s test suite:
pnpm test:lesson 2It runs lesson-verification/Lesson 2.ts and stands in spies for next/cache so the cached bodies execute and it can capture which profile and which tags each read emits — there is no live cache under Vitest. Expect every assertion green, covering the scoped tag strings, the minutes/hours profiles, the tag each read stamps, the fetchedAt field, the determinism of a fixed argument set, the empty-seed fallback, and the absence of session reads inside the bodies. A failing assertion names the read and the missing piece — for example, that listInvoices never called cacheLife, or that a cached body reached for request-scoped state.
The suite proves the directive stack is wired; it cannot prove the live cache actually holds values, because it never boots one. Confirm that part by hand against the running dev server and the inspector:
/invoices; note listFetchedAt and summaryFetchedAt. Reload promptly — both are unchanged./invoices, reload promptly, and confirm the same listFetchedAt.?status=paid; listFetchedAt is new for the new arguments; reload and it holds steady.fetchedAt; reload and it holds steady.cacheLife readout shows listInvoices: 'minutes', getInvoiceDetail: 'minutes', getOrgInvoiceSummary: 'hours'.org: and invoice: outside tags.ts and the cached reads — zero hits at any other site.Caching demonstrably works now. But there is no invalidation path anywhere yet, so a write leaves these entries stale until their cacheLife window expires on its own — edit an invoice from the inspector and the list will keep showing the old value for up to a few minutes. The next two lessons close that gap: read-your-writes from the actions, then eventual invalidation from a background job.